在开发中,许多开发模式也就不知不觉被我们运用到了,设计模式一书可以加深我们对这些概念的理解,或者说让我们头脑里有这种概念。
对《javascript设计模式与开发实践》一书的设计模式稍微做了点总结:
- 单例模式
- 惰性模式
- 策略模式
- 代理模式
- 保护代理
- 虚拟代理
- 缓存代理
- 迭代器模式
①单例模式
名称代表用法,指保证一个类只有一个实例(原理:用一个变量标志当前某个对象是否创建过,如果创建过则返回之前创建过的对象)。1
2
3
4
5
6
7
8
9
10
11
12
13
14var Human = function(name,age){
this.name = name;
this.age = age;
this.obj = null;
};
Human.Stupid = function(name,age){
if(!this.obj){
this.obj = new Human(name,age);
};
return this.obj;
};
var people1 = Human.stupid('烧饼');
var people2 = Human.stupid('Touko');
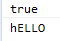
console.log(people1===people2); //true
衍生出一个知识点:惰性单例 ,只在需要时才创建对象实例,并且只创建唯一一个。
②策略模式
生活中我们要到达一个地方有很多种方法,比如去广州,可以搭大巴,也可以搭高铁的啦。要实现某个功能有多种方式可选择(原理:定义一系列的功能并把他们封装起来,使他们可以相互替换)。
使用策略模式定义算法要把算法和使用算法分离开来。稍微对书中的实例进行修改,可能比书中具有灵活性一点点点。WoW
1 | var strategies = { //用于计算奖金内容的函数 |
③代理模式
代码模式可是说成中介,假如我现在有事不方便出门,我让我弟弟代替我出门买东西。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17var yomtaaa={
shoppingn:function(target){
var money = 100;
target.payment(money);
}
};
var B = {
payment:function(money){
seller.gathering(money);
}
};
var seller = {
gathering:function(money){
console.log('收到钱为'+money);
}
};
yomtaaa.shoppingn(B);
有待更新….






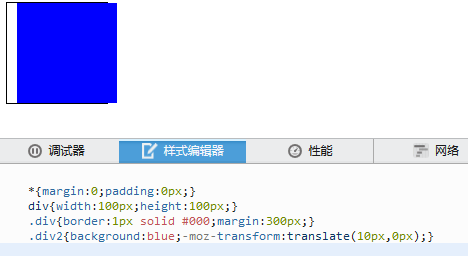
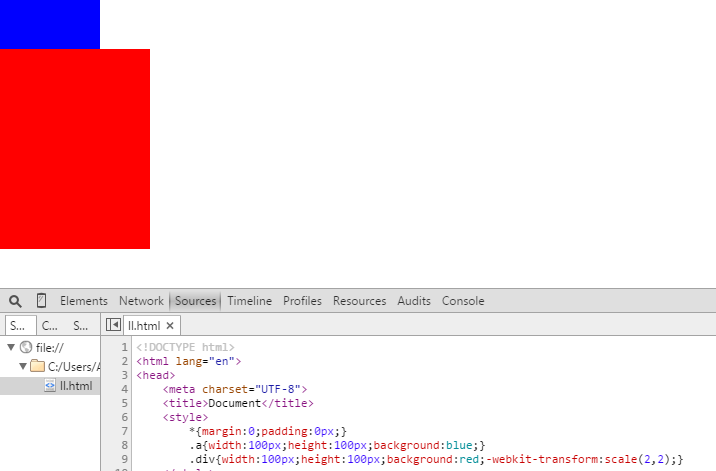
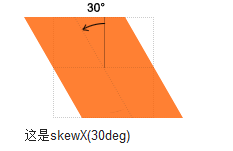
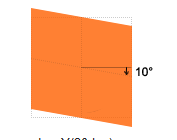
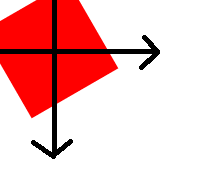 transform的旋转是根据中心点进行旋转的,这一点可以用transform-origin来改变。注意,无论你如何旋转offsetWidth、offsetHeight、offsetLeft、offsetTop始终不变,始终是默认不旋转时的值。
transform的旋转是根据中心点进行旋转的,这一点可以用transform-origin来改变。注意,无论你如何旋转offsetWidth、offsetHeight、offsetLeft、offsetTop始终不变,始终是默认不旋转时的值。